
write through
장점
간단하고 빠르다 cache logic 따로 구현해서 bus 비는지 체크할필요도 없다
단점
트래픽 많아져서 write buffer 다차면 cpu blocking 생길 수 있다.
write back
장점
memory access 효율성 올라간다 메모리를 random access하는거보다 sequence access하는게 빠르다. 한방에 몰아주니까 sequence access로 write해서 빨라진다?
단점
구현할게 많아진다
이걸 섞어서
- cpu - L1 dirty bit 저장할데도없고 자연적으로 wirte through 써야함
- 그 뒤부터 L1에 dirty bit 넣어서 write back 사용한다.
Cache 성능 향상
1. miss rate를 줄이고
2. miss penalty도 줄여야한다.
1을 위해서
place 알고리즘을 잘짜서 hit 확률을 높힌다
cache size를 늘려서 hit 확률을 높힌다
2를 위해서
level을 여러개 만들어서 miss나도 다음 level로 가면 penalty 줄일 수 있다. 바로 dram가는거보단 낫다.
3. spatial locality
word 가져올 때 주변에 있는 word도 같이 가져온다.

한번에 얼마나 가져올지 고민해 봐야한다. 많이가져오면 가져온거에다가 tag 하나 붙이면되니까 효율이 좋다.
하지만
많이 가져오면 hit rate가 줄어든다
그렇다고 너무 적게 가져오면 spatial locality가 반영 안된다. 그래서 벤치 돌려서 적정값을 찾아한다.

그렇다면 이 주소를 보고 어떻게 메모리를 찾을까?
Block index 보고 index 찾아서 tag랑 비교해서 같은지 비교한다.
그럼 cache가 tag + word word word word 이렇게 되 있으니까 word offset으로 data 반환한다. Byte offset은 해다 ㅇword의 byte 고를 때 쓰는거 (char 같은 경우 한 byte씩 접근할 일도 있으니까 그때 쓴다)
요새는 word가 8개 16개 한번에 다룬다.
cache size : 2^14 bit (index) * 16 byte(4 word) = 256kb

그렇다면 이제 blockoffset을 이용해 mux로 data를 고르는 작업까지 추가된다.
blcoksize와 miss rate 관계

blocksize가 커지면 entry는 줄어들고 cache size가 작아진다.
처음에는 spatial locality 때문에 hit rate가 올라가지만(miss rate 감소) 임계값 지나면 cache size(total blocks in cache)가 줄어들어서 miss rate가 점점 커진다.
block size가 커지면 spatial locality 특성 때문에 miss rate가 줄어든다.
하지만 그만큼 miss penalty가 커지고 block size가 커질수록 block 개수(cache size)는 줄어들고 그럼 miss rate가 커지게됨.
Fully associative cache(Flexible placement)

direct mappped 인 경우를 생각해보자 만약 우연하게 ws1 ws2 ws3 순서대로 계속 사용한다면 cache L1은 계속 miss나면서 일정부분만 사용함.
이런 방법은 temporal locality 특성을 활용 못하는거다. 위에서 word 개수를 늘려 spatial locality를 극대화 했듯이 이번에는 temporal locality 특성을 살려보자.
Fully associative cache 방식은 모든 index에 다 들어갈 수 있다. 구체적으로는 timestamp를 만들어 old한 index가 replace 되는 방식이다. 따라서 temporal locality 특성을 극대화 한 방법

단점 : hw 용량이 커진다.
1. index가 아닌 tag만을 이용해서 값을 찾으니까 tag bit이 커짐
2. 이전의 방식은 = or 두개의 gate를 사용해서 hit을 알 수 있었는데 이 방식은 cache index 개수만큼 + hit or gate까지 겁나 많이 필요함.
N-way Set Associative

Direct와 Fully Associateive 의 중간에서 만나는게 n-way 방법
2등분 4등분해서 절충안으로 쓴다.
4-way Set Associative

full-way에 비하면 temporal locality를 잘 활용하지 못하지만 hw를 줄일 수 있다.
Instruction and Data caches
data와 insturction cache는 분리하는게 좋다.
요약




L1에서는 스피드가 생명이기 때문에 hit rate가 좀 낮아도 2-way 만 쓴다 way 를 늘릴수록 hw가 커지고 속도가 느려지기 때문
그 뒤 level부터는 좀 더 많은 way 가능
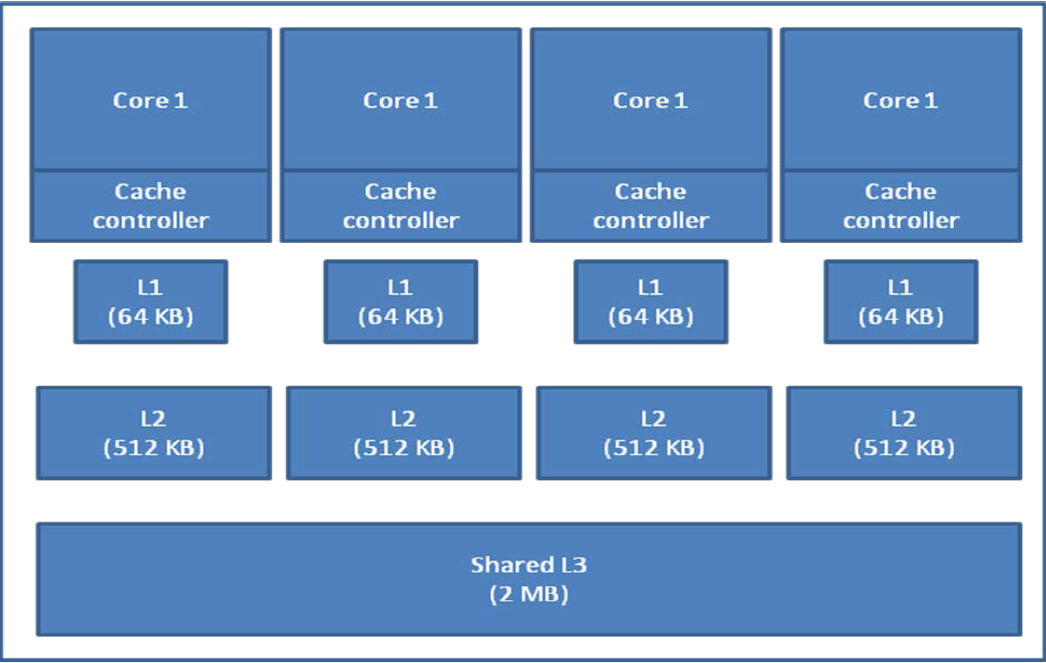
전체적인 메모리 구조
Level 1은 무조건 각각 있어야 한다 (속도가 생명) 그 뒤부터는 어차피 느리기 때문에 공유할 수도 아닐수도 있음
'학교공부 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조23 - Virtual Memory (0) | 2020.06.25 |
|---|---|
| 컴퓨터 구조 21 - Cache (0) | 2020.06.20 |
| 컴퓨터구조 18 - SMT (0) | 2020.06.17 |
| 컴퓨터구조 17 - SMT (0) | 2020.06.17 |
| 컴퓨터구조 16 - Multithreading (1) | 2020.06.17 |



