Multi threading 종류
- Fine-grained MT
- Coarse-grained MT
- Simultaneous MT
이전에 위에 두개 배웠다. 각각 장단점이 존재한다.
FG와 CG MT에서는 결국 한 클락안에서는 한 쓰레드를 갖고온다.
SMT의 idea는 한 클락에서 multi thread의 명령어를 갖고오는거.
이전에 배운 superscalar 진행을 보자

single thread 상황에서 많은 hazard가 생겼다.
지금까지 배운 방법을 superscalar 적용해보자
1. predicated Execution
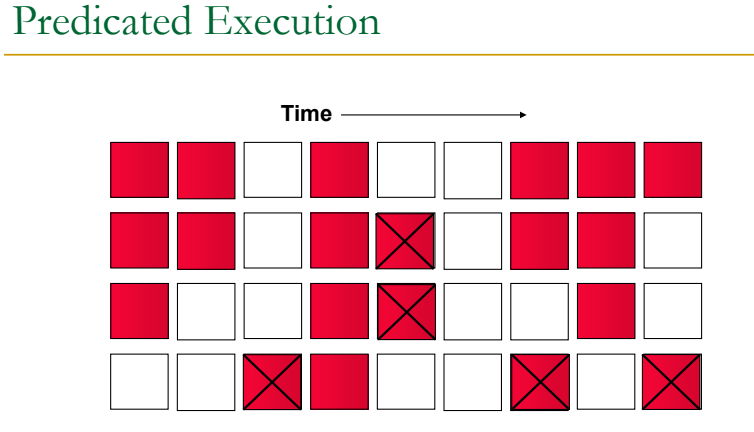
branch를 없애고 성능 쪼금 향상돼도 어차피 nop있어서 별다를거 없다.
2. Chip Multiprocessor

멀티프로세서 환경이라면 아예 분리가 되니까 잘만 짜면은(높은 가동률) 성능 배속향상 기대할 수 있다.
근데 multi threading보다 hw가 더 필요하니까 cost 손해임
3. FG
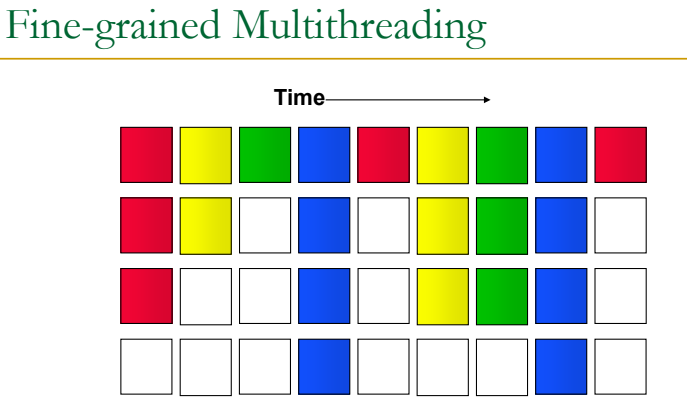
매클락마다 다른 thread가 돌아가니까 전체 시스템 성능은 향상된다.
근데 빨간색 입장(single process)에서는 손해임.
그래서 나온 기술이 SMT다.
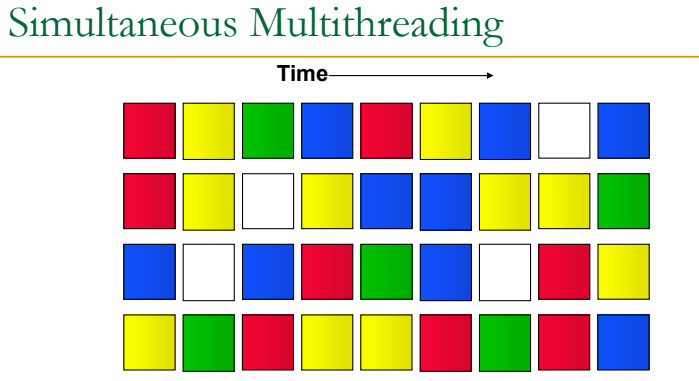
SMT는 뭐냐? 한 클락에 쓸수있는거 그냥 다 가져오는거다. 버블 많이 줄어서 좋다.
추가로 thread간에 우선순위를 부여해서 필요한거 먼저 처리하면 이전에 FG, MT에서 생겼던 single thread performance suffers도 줄일 수 있다. 결국 다 좋다. 단점이 거의 없는 아이디어.
+ 만약 첫번째 clock에서 파란색이 branch라고 하자. 그럼 다음 clock부터 파란색 thread의 instruction을 적게 가져오는 방법을 쓴다던지 높은 priorty thread가 있다면 먼저 다 채워준다는 등의 여러 policy로 전체 성능과 single thread 성능을 둘다 컨트롤 할 수 있다.
근데 구현하는게 어려움 딱봐도어려워보인다 dependency 관리 multi threading 관리 등등 짤게 많다.
옛날에 amd가 smt 포기하고 불도저 냈는데 고대로 망해버림 그래서추가해서 나온게 라이젠이라는데 암튼 smt가 좋다이말임
SMT Pipeline
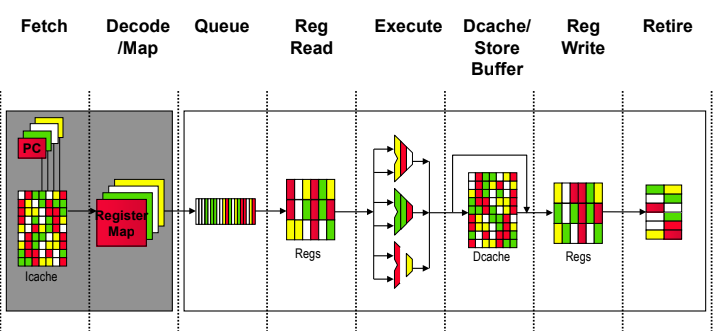
Fetch,Decode : 명령어 가져온다.
Register Map : 명령어가 들어왔을때 register주소를 실제 physical한 주소로 mapping, data dependence 해결위해 renaming 등등
Queue : loop unrolling 등 명령어 작업한다. (이게 instruction queue)
(hw에서 작업한다 sw에서 작업했으면 루프다풀면 exe파일 크기 커지는데 hw에서 해서 효율적)
각각 쓰레드별로 막 들어가서 작동한다.
사실 뭔말인지는 잘 모르겠고 결론은 fetch부터 register data execute 다 뒤죽박죽 마음대로 하는거임. 이걸 user입장에서는 그냥 순서대로 하는것처럼 느껴지게 잘 설계해줘야한다.
단점 : high cost
SMT를 위해서 뭐가 필요하나?

추가적인 resource
1. PC
2. Register Map
3. Return address stack
4. GHR
들이 추가적으로 각각의 thread마다 있어야한다.
공유하는 resource
1. Register File (이건 추가적으로 할수도있고 공유할수도있음. 부족하면 size increased 해서 공유할수도있고 아님 그냥 쓸수도있고 추가적으로 각각 달수도있고 상황따라 다르다.)
2. instruction queue
3. cache
4. TLB
5. Branch Predictor (이것도 공유할수도있고 추가적으로 복제해서 각각의 thread마다 달수도있음 cost와 성능사이에서 적절하게 고민한다)
Register file인 경우 shared해서 동적으로 배분하기도하고 등등 여러방법을 쓴다.

out of order + smt = 최고의 방법
위에서 말했듯이 여러 추가적인 hw와 규칙이 필요하다

superscalar 4개짜리인 경우 몇개의 multi thread가 효율적인가? 이런걸 실험해서 최적의 환경을 찾는거다.
'학교공부 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터 구조 21 - Cache (0) | 2020.06.20 |
|---|---|
| 컴퓨터구조 18 - SMT (0) | 2020.06.17 |
| 컴퓨터구조 16 - Multithreading (1) | 2020.06.17 |
| 컴퓨터구조 15 - SuperScalar (0) | 2020.06.17 |
| 컴퓨터구조 - 14(Predicated execution, Loop Unroll) (0) | 2020.06.17 |



