Motivation
hadoop 은 streaming(real time) processing 에는 약하다
why is Mapreduce weak in iteration job?
maping 과정 후 중간값을 file system에 temporary하게 저장하고 reduce가 그걸 가져와서 작업하고 hdfs에 올린다.
이렇게 file system에 접근할수록 속도가 낮아진다. (disk 접근)

하지만 스파크는
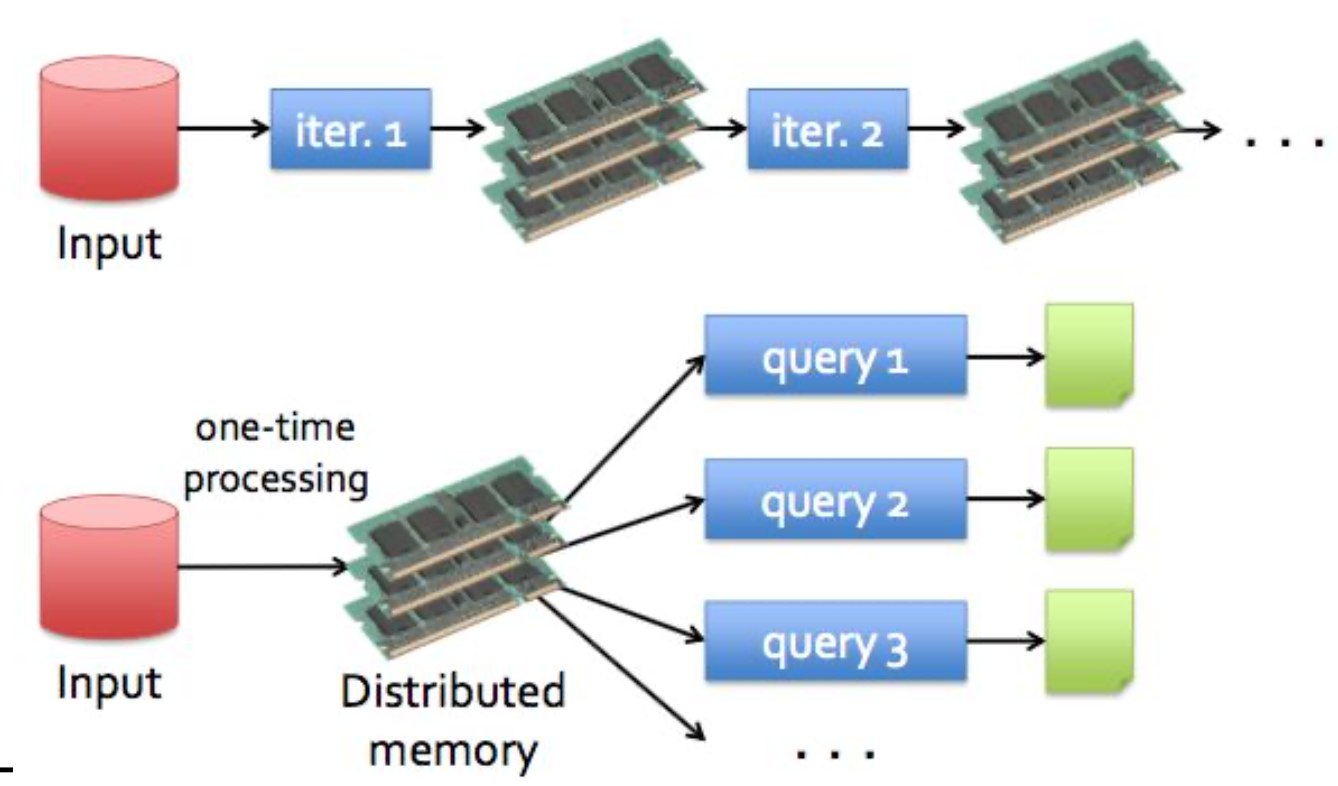
메모리에 올려서 작업해서 개이득
결론적으로 spark는 in-memory system이라 I/o system인 mapreduce보다 빠르다.

Spark
RDD
기본적인 data set (read-only)
immutable
partitioned collections of records
be able to contain any type of python, java, or scala
spark function에는 두가지가 있다
Transformations & Actions

Transformations :
Transformations are operations on RDDs that return a new RDD. As discussed in “Lazy Evaluation” transformed RDDs are computed lazily, only when you use them in an action.
transformation은 rdd에서 새로운 rdd 만드는것
연산을 바로 실행하지 않고 action을 실행하는 시점에 최적의 방법으로 실행한다. 그래서 효율적임 ㅇㅇ
transformation의 map function

뭐 여러개 있음 알아서 자료 보자
Actions:
collect, count 등등
이러한 perform을 어떻게 효과적으로 하냐?
Lazy Evaluation -> Optimal Cost
transformation 바로 실행하지 않고 action할 때 한방에 최적의 방법찾아서 실행한다. optimal
MAPREDUCE : DISK IO 때문에 반복작업 시 효율이 매우 안좋아짐.
RDD(Rdesilient Distributed Datasets)
RDD는 memory에 올려서 속도 빠름 ㅇㅇ

RDD는 dataset 덩어리 모음
덩어리들이 분산되어있다.
read only 수정 불가능
새로운 RDD만들어 내야된다.
RDD의 연산으로 새로운 RDD를 만들어낸다.
이 연산을 기록해서 error나도 복구가능
RDD 명령어는 크게 Transformation과 Action으로 나눠진다.
Transformation은 RDD로 새로운 RDD를 만들어내는거고 // transformation : map, filter, join..
Action은 RDD에서 결과값을 만들어내는거
근데 Action이 실행되기전까지 Transformation은 실제로는 실행되지않고 기록만하다가 action이 실행되면 그때 작동함.
RDD는 Coarse-grained 단순한 연산. 고장났을 때 복구 편하다. 명령어만 다시 넣으면된다.
10/27
value pairs


groupbykey는 다올리는거고 reducebykey는 중간에 연산한번해서 보내는거라 효율적이다.
reducebykey가 좋다 ㅇㅇ

뭐 대충 이런데이터 있다고 보면 특정 key에 data가 몰릴수있다.
key aren't evenly distributed 이런것도 고민해 봐야된다.
한번 읽어봐라


fillter


스파크에선 집합 함수 제공 뭐 암튼 뭐뭐있으니까 pdf 읽어보셈


왼쪽조인 오른쪽 조인 알지? 한번 읽어보셈

sorting 오름차순 내림차순 등등

람다써서 몇번째 값 기준으로 sorting할건지 정할 수 있따.

재사용시 성능 이득 볼 수 있다.

5분동안 유저가 검색한거 저장하는거임
user정보는 static event 정보는 dynamic함
근데 문제가있음 뭘까?

보통 Userdata가 evnet보다 훨씬 크겠지? 그럼 조인연산할때 shuffle연산도 많이 일어나고 암튼 개손해임
근데 파티셔닝 쓰면 개꿀
rdd를 기준에 따라 그룹화하는거
luminousmen.com/post/spark-partitions

처음에는 한번 shuffle해서 partition한 후 persist(저장)하면 다음주터는 shuffle 안한다. 1번은 shuffle해야됨.


이런식으로 partitioning하면 좋다.
저장하기위해선 persist 사용해야한다
// rdd는 수정안되니까 무조건 새로 만들어서 저장해야됨 저장하는데는 주로 persist나 cache사용
partioning 과정
webdevdesigner.com/q/how-does-hashpartitioner-work-3732/
var rdd1 = sc.parallelize(List(1, None), (1, None), (2, None), (2, None), (3, None), (3, None), 8)
var rdd2 = rdd1.partitionBy(new HasPartitioner(2))


요건 hash값을 1로한거

느니까 아무렇게 join하지말고 잘생각해서 partition도 적용해보자
map에서는 partition안된다
hash range partition 한번 읽어보셈
파티션 장점

12/04
partitioning 추가적으로 한다.
persist중요하다

reuse함으로써 이득임

메모리에 쓸거냐 DISK에 쓸거냐. 직렬화 할거냐 말거냐 등등

cache되어있는게 persist되어있다는거임.
한번 저장해논거 계속 불러와서 사용 가능
val input = sc.textFile("bigdata")
val result = input.colesce(600).persist(StorageLevel.DISK_ONLY)
result.count()
// and repeat command
result.count()// read, shuffle(partition), persist, count
첫번째에서는 read shuffle persist count 과정을 거친다.
하지만 두번째부터는 from persisted copy된거로부터 바로 read - count한다.
MEMORY_ONLY_SER : 공간 절약위해서 직렬화한다.

직렬화를 하면 성능상은 이득이지만

처리시간에 trade off가 있다.

small data set인경우 raw caching하는게 합리적일 수 있다.
근데 데이터가 크다? 그럼 serialized 해서 footprint(차지하는 공간) 줄이는게 좋다.
2~4배 space를 더 차지한다는게 뭐냐?
data가 100mb라면 실제로 저장하면 200~400 mb 저장할 수도있다. 자바 object를 다 저장해야해서 근데 serialized를하면 오버헤드 쪼금먹고 이득가능
스파크의 data load방법

그뒤에 걍 읽어보셈~

스파크는 구조상 전역변수 유지가 힘들다
클러스터구조면 당연히 안되겠찌? 다 나눠져 있으니까
그래서 closure란게 생겼다

코드 실행이 끝나고도 persistent되는 것?

closure을 반환하면 계속 참조하고있다.
closures in local vs cluster modes ?

local모드에서는 합리적으로 나올수도 있는데 cluster mode에서는 알 수가 없음

그래서 필요한게 Accumulators

write only에 더하기만 제공
이거 코드 잘봐야될듯?
왜 마지막에 선언하냐? lazy evaluation랑 비슷하다 결과 계산이 끝난후에 써야지 정확한 값을 볼 수 있다.


위 상황때 보통 accu사용한다. count알기 위해
'학교공부 > 빅데이터프로그래밍' 카테고리의 다른 글
| Hadoop Basics 1 (0) | 2020.09.23 |
|---|---|
| 빅데이터 프로그래밍 개요 (0) | 2020.09.21 |

