
structured data : schema가 정해져 있는 데이터 exel
semi-structured data : Json
unstructured data : 구조 x 이미지 등등
hadoop은 어느 데이터를 처리할 수 있냐 고민해봐야됨

hadoop 에서는 정규화 안된 데이터들이 많이 들어옴.
데이터베이스 정규화란 데이터의 중복을 줄이고 무결성을 향상 시키는 등 여러 목적을 달성하기 위해 관계형 데이터베이스를 정규화된 형태로 재디자인하는 것을 말함.
haddop은 비정규화된 데이터도 처리할 수 있다.
데이터 정규화

1차 정규화
atomic column 중복을 제거한다.
Adam 두개니까 제거
2차 정규화
중복을 제거한다.

scale up과 scale out이 있다.
scale up : 한 컴퓨터의 성능을 좋게 하는것. (메모리 추가하고, cpu 더사고 등등)
scale out : commodity 머신을 더 붙여서 성능 향상.
scaling이란 만약 우리가 scale out을 2배하면 작업속도도 2배 빨라져야된다는 것.

이거정도는 외어야됨.
access batch interactive 힘듬.
Updates는 특히 중요함. Write once 다시 쓸순 있는데 데이터 수정은 안됨. 대용량 데이터 처리를 위해 컨셉을 잡은거.
하둡 무결성은 low
scaling lilnear scaling에 따라 성능이 lenear하게 변화한다.
근데 요즘은 시대가 발전해서 꼭 이런건 아니래~
parallel에서 문제점
나누기 힘들다
또 합치는데 cost 발생
단일 머신 처리능력은 한계가 있다
이런 문제를 하둡은 해결 가능

하둡은 key value로 처리해서 가능하다?

map에서 각 연도별 숫자 뽑고
reduce에서 interator로 숫자 세고
output에서 젤 큰거 뽑는 과정
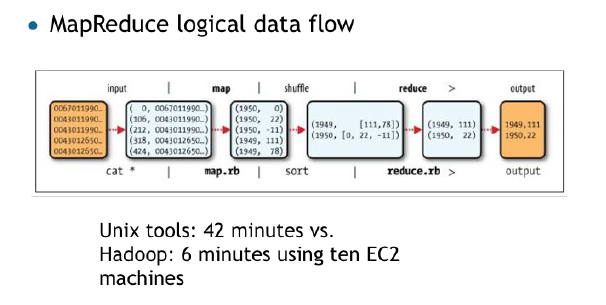
unix 에서 42분걸렸는데 hadoop에서 6분걸렸대
Mapper foramt
public class MaxTemperatureMapper
extends Mapper<LongWirtable, Text, Text, IntWritable>
앞에 두개 Input key, value
뒤에 두개 output key value datatype
Reducer
public class MaxTemperatureReducer
extends Mapper<Text, IntWritable, Text, IntWritable>
mapper
앞에 0, 106 이런게 offset 그다음 오는 긴게 Text다
그리고 (1950,0) 을 보면 앞에는 Text 뒤에는 Int를 뽑아내고 있다.
reducer
마찬가지 Text,int형태로 들어와서 Text,Int 형태로 나간다.
Java MapReduce
실제 코드에서 (chapter 3 , 27p)

Input에 path Output path 설정해줘야한다.
output에서 만약 path가 이미 있는 path라면 overwrite하지 않고 reject한다. (오랫동안 작업한거 아까워서 그러는듯 실수했다간 타격 크자너 ㅋㅋ)
9/25

HDFS : 네트워크를 통해 연결된 여러 머신의 storage를 관리하는 시스템
여러 문제가 있고 그걸 복구하는걸 고민해봐야됨.
Trade off
Low-latency data access
: 하둡은 latency보다 얼마나 많은 양을 처리하는데 중점을 둠
Lots of small files
: 작은 파일 단위로 저장 안됨.
Multiple writer, aribitary file modification
: 동시 쓰기 안되고 아예 다시써야됨.
Blocks
disk가 읽고쓰는 가장 작은 단위
hdfs는 128MB가 default임
일반적인 disk block보다 단위가 겁나 클까?
일괄처리 ㅅㅌㅊ
탐색비용 최소화
replication에서 이점있음
Namenode Datanodes
master -slave 관계
namenode : filesystem namespace 관리
datanode : data 저장
heartbeat : datanode가 namenode에게 자신이 alive하다는 신호를 3초마다 준다. namenode에서 이거보고 상태 확인 가능
namenode 복구 방법
1. 백업
2. secondary namenode
namenode 문제생기면 run a secondary namenode
single point of failure (SPOF)
namenode 고장나면 전체적인 job에 문제가 생길 수 있음
active stanby configuration 이것도 secondary namenode랑 비슷하게 고장낫을때 대처방법인듯


하둡 설정에서 위처럼 다양한 인터페이스로 filesystem 여러 환경에서 사용가능
우리 수업에선 HDFS사용

conf에 맞게 file 읽어온다.

fs.open을 하면 FSDataInputStream 형식으로 받아온다.
Seekable이나 PositionedReadable 인터페이스로 가져옴 따라서 읽은 데이터는 FSData 머시기에 지원해주는 기능들을 읽을 수 있는거임
PositionedReadable은 그냥 데이터 읽어오는거
Seekable은 getPos랑 seek가 있는데, seek는 탐색 random access, 근데 하둡에선 순차적 읽기라서 seek해서 읽으면 비용이 많이듬
getpos는 position에 대한거 반환

writing Data


getPos 마찬가지로 데이터의 position 반환
seek은 지원하지않음 왜냐? HDFS는 sequential write만 지원하기 때문. 아예 새로 쓰던지 쓰던거 뒤에 쓰는거만되지 update는 안된다는 거인듯.
Data Flow

client node : 내 노드
FILE READ
1. open(): client에서 default FS conf를 통해 open()을 이용하여 원하는 파일을 연다
2. get block locatioins: 파일의 첫번째 block위치를 파악하기 위해 namenode에 요청 / replication(data node의 유실을 위해 만든 복제본) location 주소 반환 (가까운 네트워크 topology에 따라 정렬후)
3. DistributedFileSystem > FSDataInputStream 반환하여 데이터를 읽을 수 있음
4. Clien는 스트림을 읽기위하여 첫번째 블록의 데이터 노드 저장 및 read() 계속 호출하여 데이터노드가 client 노드에게 데이터 전송
5. 블록의 끝에 도달하면 InputStream은 데이터노드의 연결을 닫고 다음 데이터 노드를 찾는다.
network topology

노드간에 distance를 보자.
하둡은 네트워크 대역폭을 하나의 트리로 생각한다
동일 노드는 당연히 distance 0, replica의 location을 요런 규칙으로 가까운거 쓴다? 이런느낌인가
distance가 작을 수록 대역폭이 크다

위에건 읽기고 이번엔 쓰기과정을 보자
1,2 distributeFileSystem에서 namenode를 통해 파일생성하고 검증함.
3. DistrubuteFS에서 FSDataOuputStream 반환해줌, data를 packet으로 split한다음 queue로 쏜다.
4. Data Streamer가 data 쓴다. replica가 있으면 개들한테도 쓴다
5. data다 보내면 ack 신호 받고 확인완료.

내구성을 위해서 복구할때 쓸라고 저장해놓는거.
첫번째는 자기 rack에 있는 곳에 복사(자기 node) 두번째는 다른 rack에 있는 node에 복사 세번째는 다른 node의 같은 rack에 배치한다.
만약 하나의 데이터노드가 죽으면 다른곳에서 가져오면 되고 만약 전체 rack이 죽으면 다른 rack에서 복구할 수 있다.
신뢰성 vs Write, Read 대역폭
1. 쓰기 대역폭을 줄이기 위해 단일 노드에 모든 replica를 배치할 경우
2. 외부 rack에 다 쓰게 될 경우 -> read시 band width 많이 잡아먹는다.
trade off 관계
band width (대역폭) 대충 한 네트워크에서 단위시간에 전달하는 최대 용량 같은 느낌
bandwidth가 크다는거는 동일 시간에 많이 보낸다는 뜻
bandwidth <-> latency trade off 관계
5개 노드가 있는 cluster에 두 개의 파일이 들어간다고 생각해보자
file1 - > block1, block2
file2 -> block3, block4


특정 노드안에 붙어있는 데이터 노드들은 band-width가 많고 latency가 적다.
노드가 떨어져있으면 less bandwidth higher latency
위 그림에서 문제점을 보자
같은 rack에 replica 몰아넣으면 신뢰성 하락
Data Locality

위에 replica랑 조금 다른건데 이건 Map task에 관한거임
모든 노드가 다 바빠서 다른 rack으로 가는 C인 경우는 희박한 경우임
당연히 A>B>C 순으로 bandwidth 높다.
YARN
Hadoop's cluster resource manager

YARN은 크게 두개로 이뤄져 있다.


실행 과정을 보자

1. Application은 뭐 마스터 같은거임 mapreduce나 spark돌릴 때 각각 하나씩 생긴다고 생각하면 된다.
2. 그다음 resoure manager는 container에서 application을 실행시킬 node manager를 찾는다.
3,4. 만약 하나의 노드에서 하기엔 너무 큰 작업이면 다시 resource manager한테 알려준다음 다른 nodemanager한테 작업 나눠준다.

container의 지역성도 support함
yarn은 리소스 요청을 언제든지 만들수 있다. 미리 할당(front)하거나 dynamic으로 할당 가능
중요한건 MR1 이랑 YARN의 차이

yarn에서는 jobtracker의 일을 분리했다.
MR1이랑 비교했을 때 YARN의 장점
● Scalability
● Availability
● Utilization
● Multitenancy
Scalability 확장성
jobtracker에서는 job과 task를 모두 관리하고있어서 병목현상이 생길 수 있다.
yarn은 분리되어있어서 큰 클러스터 가능
Availability 가용성
jobtracker는 크고 빠르게 바껴서 복사 불가능한데 yarn은 분리되어있어서 state replicating 가능
Utilization ★★★
mr1에서는 slot을 고정된 크기로 할당해놓고 map slot은 map task가 reduce slot은 reduce task에서만 사용 가능했다.
yarn에서는 node manager가 resource를 pool 느낌으로 관리한다. 마치 큰 pool장에서 resource ball을 넣고 필요할때마다 하나씩 주는 느낌 자유롭게 사용가능
Multitenancy
yarn을 통해서 mapreduce 뿐만아니라 다른 application 붙이기 가능(spark 등등)
Scheduling in YARN

1. FIFO
간단하지만 큰 application 실행되면 cluster 점유해버림
2. capacity scheduler
fifo 보다는 효율적
큐 별로 사용할 수 있는 자원의 총량을 정해놓고 처리하는 방식이라 cluster 전체 측면에서 보면 효율 하락
3. fair scheduler
자연을 동적으로 분배
큰일하다가 작은 일나오면 fair하게 분배해서 준다.
2번째 job이 오면 바로 할당은 못하고 fair하게 계산하는데 latency 약간 있음
4. delay scheduling
data locality를 위해서 바쁜 node에 task가 끝날때 까지 기다렸다가 할당해주는게 나을까 아님 그냥 다른데다 하는게 좋을까
만약 좀만 기다리면 locality 살릴수 있으니까 기다렸다가 스케줄링한다.

한번 읽어보기
Hadoop I/O

block은 물리적인 개념 split은 논리적은 개념
block 은 128mb로 저장된다.
split은 논리적으로 어떻게 가져가는가
만약 text line을 split한다고 할 때 정확하게 안쪼개지면 어떻하냐? 위그림에서 8번처럼 딱딱 안끊어지면 어떻게 처리할까?

과연 각 mapper들이 어떻게 읽을까?
start 와 actual start end를 보자 RecordReader가 저렇게 잘 쪼개준다.
다른 예제를 보자

| start | actual start | end | line | |
| mapper 1 | 0 | 0 | 300 | line 1 |
| mapper 2 | b2: 128 | b1: 300 | b2: 256 | n/a |
| mapper 3 | b3: 256 | b3:300 | b5:600 | line2 |
각 라인마다 mapper가 할당된다.
다음 예시


data locality
There is here some overhead as we’re trying to read a lot of data that is not locally available
Do not process a line that is not starting in the chunk I’m responsible for (내가 책임지는 chunk()에서 시작하는거 아니면 신경안씀 )
Data Integrity
check sum을 통해 무결성 체크
-
HDFS transparently checksums all data written to it and by default verifies checksums when reading data
write할때 checksum 계산하고 read할때 확인 에러나면 ChecksumException 받음
만약 checksum 자체가 corrupted 하면 그냥 처리하지 않음.
그냥 ppt 한번 읽어보셈 ㅇㅇ
Compresstion
장점
-
Reducing the space needed to store files
-
Speeding up data transfer across the network or to or from disk
이것도 한번 읽어봐라
Compression and Input Splits
HDFS block size of 128MB, uncompressed file 1GB = 8 input splits
Gzip compressed file 1GB - impossible | Bzip2 compressed file - possible
Bzip2는 splittable이 지원돼서

중요한건 splittable을 지원하냐? 이다.
splittable이 뭐냐?
bzip2 does provide the market between blocks, so it does support splitting
자 생각해봐라 1GB는 파일은 128메가로 8개로 쪼개서 저장할수 있다 지역성을 살릴 수 있음
근데 1GB짜리 압축파일이있는데 얘가 split 지원하지 않는다? 그럼 이거 map task 하나가 통째로 처리해야됨. 개손해임
그럼 큰 file을 gzip으로 압축하면?
data locality 잃어서 손해다.
Serialization
Serialization는 네트워크로 보내기위해서 byte stream으로 만드는거
DeSerialization는 다시 structured object로 만드는거
RPC remote procedure call
이것도 대강 한 보셈
client에서 server의 함수를 네트워크를 통해서 자기것처럼 사용하는거
RPC 직렬화 장점
compact fast extensible interoperable
직렬화 걍 한번 읽어보셈 ㅇㅇ
그 뒤 avro 이런건 걍 알아서 찾아보셈 ㅅㄱ
// 그냥 추가된거
combiner 역할
map -> combine or not -> reduce
만약 map 에서 john 1 * 100개라면 band width 줄어든다. 따라서 백번 보내는게아니라 mapper 끝난다음 거기서 한번 개산해서 john 100 보내면 개이득.
중간고사 : 논문 기본적인 백그라운드를 위해 처음부터 3.2 other assumptions까지만 읽어보시면 됩니다.
강조한거 위주로 skip한거 안봐도됨.
config에서 local localhost cluster에서 돌릴 수 있게 지원해줌

reduce 개수 늘리면 병렬처리 늘어서 계산량이 줄긴 하게ㅅ지만 너무 많이 늘리면 너무 작고 많은 파일이 생겨서 오히려 문제가 될 수도 있음
task execution
특정 task가 느려지면 모든 작업에 영향줄 수 있음
너무 느려진다 싶으면 따로 실행시켜준다.
'학교공부 > 빅데이터프로그래밍' 카테고리의 다른 글
| Spark (0) | 2020.11.15 |
|---|---|
| 빅데이터 프로그래밍 개요 (0) | 2020.09.21 |

