Why we need Hadoop for Big Data?
Data Storage and Analysis
We already knew even though storage capacities or performance of hardware, e.g., HDD, SDD
have increased a lot over the years access speeds.
e.g., drive from 1990 year could store 1,370MB of data had a transfer speed of 4.4MB/s.
20 years later, 1-terabyte hard drive are normal, but the transfer speed is around 100MB/s
Problem?
A long time to read all data on a single drive and writing is even much slower !
Solution?
reducing the time is to read from multiple disks at once in split data. e.g., 100 drives, time?
용량은 겁나 커졌는데 단일 드라이버에서 읽고 쓰는게 느리다.
Users must be happy to share access from multiple drives in return for shorter analysis times !
Problem?
1. Hardware-failure: the chance that one drive would be failed is fairly high
2. Combining outputs from complete tasks like 99 drives?
- many distributed systems allow data to be combined from multiple sources,
but doing it correctly is challenging.
Solution?
1. guess? e.g., RAID, HDFS
2. guess? e.g., MapReduce
drive 분산하면 distrivute 하고 combine도 고민해야됨
MapReduce
하둡에 지원하는 프로그래밍 모델

ex) 왼쪽 txt데이터를 스크립트로 분석
mapper에서는 데이터에서 이름 추출
reducer에서는 카운트
맵리듀스는 맵(Map) 단계와 리듀스(Reduce) 단계로 처리 과정을 나누어 작업
각 단계는 입력과 출력으로써 키-값 쌍을 가지고 있고, 그 타입은 프로그래머가 선택합니다. 또한, 맵과 리듀스 함수도 프로그래머가 직접 작성하게 됩니다
Map은 흩어져 잇는 데이터를 Key, Value의 형태로 연관성 있는 데이터 분류로 묶는 작업
Reduce는 Map화한 작업 중 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업
출처: https://over153cm.tistory.com/entry/맵리듀스MapReduce란-1 [빅데이터는 넘커]
실제 하둡에서 map
reducer
스크립트 코드보다 하둡쓰는게 좋다는 뜻
그림으로 보자
mapper key value 가져옴
sort-merge 해서 reducer에 John 개수 나옴
Replica : Host가 고장났을때 복구가능
Data locality, 만약 HOST 3 에서 SPLIT 3 가 필요할때 다른 HOST에서 네트워크로 달라고한다 -> COST 발생
그래서 다른데서 안찾게 data 잘 할당해줘야됨 -> Data locality
REDUCER은 MAPPER에서 만든 데이터 count하는거라 locality 필요없음
그리고 mapper의 개수보다 REDUCER의 개수는 현저히 적음.
Batch System
Batch processing vs streaming processing
streaming : data가 들어올때 실시간으로 처리한다.
batch : 주기적으로 돌리는 시스템. 데이터를 한번에 모와서 한방에 돌리는거.
기본적으로 MapReduce 는 batch processing system이다.
Interactive SQL
Iterative Processing, e.g, machine learning
Streaming Processing. e.g, real time
위와 같은 방식으로 MapReduce 사용하면 성능 느려짐.
MASTER - SLAVE 관계
File storage : NAME NODE - DATA NODE
MapReducer : JOB TRACKER - TASK TRACKER
name node : meta data
data node : block
NoSQL
shema free 가 왜 필요하나?
data 많은데 이거다 pasing해서 스키마에 넣는게 더 힘듬
NoSQL concept
Key/value
Document
Column 등등
하둡구조
HBase

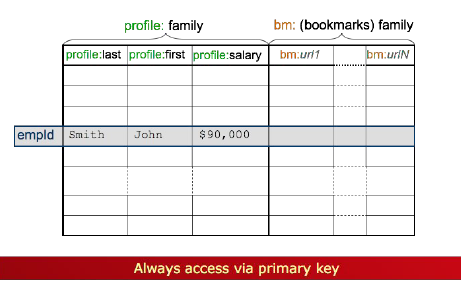
단순히 last first가 아닌 profile로 이름 붙쳐서 저장한다.
Row oriented database : 우리가 평소에 보는 가로단위 저장
Column oriented database : 세로단위 저장
ex)
Row
1, Paul Walker, US, 231 , Gallardo
2, Vin Diesel, Brazil, 520, Mustang
Column
1,2, Paul Walker, Vin Diesel, US,Brazil, 231 ,520, Gallardo, Mustang
big data 환경에서는 Column 방식이 이득임 이런 Column 방식이 HBase 나 카산드라임.
Pig
대용량 처리 언어?
하둡에서 길게 칠거 pig 언어로 간단하게 가능.
HIVE
SQL가 비슷하다.
Column 형태로 저장해야한다.
이렇게 파티셔닝하면 필요한 데이터를 쉽게 가져올 수 있다.
SQL가 비슷하지만 User Defined Function 과 같이 추가적인 기능 구현 가능.
'학교공부 > 빅데이터프로그래밍' 카테고리의 다른 글
| Spark (0) | 2020.11.15 |
|---|---|
| Hadoop Basics 1 (0) | 2020.09.23 |

