오늘 배울거

뭐 여러가지 app 돌아감
vm

vmm이 vm간에 isolation 만들어줌

장점
1. Migration

shut down해야할경우 껏다킬필요없이 alice가 다른 machine에 migration(옮기기)하면 customer은 그냥 사용하던대로 사용할 수 있음
2. Time Sharing

Multiple VMs can time-share the existing resources
Result: Alice has more virtual CPUs and virtual memory than physical resources (but not all can be active at the same time)


overcommitting resources(time sharing 같이 가지고있는거보다 더 제공하는거)
vmm 만이 컨트롤 각자는 isolation
challenges
1. Availability : 장애발생
2. Data lock_in : 다른 could로 이식
3. Data confidentiality and auditability : data 보안성
4. Data transfer bottlenecks : could의 data가 커지면 어떻게 옮길거냐
5. Performance unpredictability : 초창기에 sharing때문에 성능 예측불가
6. Scalable storage : S3(인터넷용 스토리지 서비스)
7. Bugs in large distributed systems
8. Scaling quickly
9. Reputation fate sharing
10. Software licensing
3장


scale이 커질수록 분산, 정렬 이런게 복잡해진다.

For now, assume we have multiple cores that can access the same shared memory
• Any core can access any byte; speed is uniform (no byte takes longer to read or write than any other)
• Not all machines are like that -- other models discussed later
커지면 smp구조 유지못함. 많은 core 한공간에 못때려박음(열, 기술 등등)

parallel prog의 필요성과 한계에 대해 알아보자
scalability란 무엇이냐?

늘어날수록 더 크게 제공해야되는데 결국 bottleneck을 만나는게 문제다
암튼 효율성과 speed 좋게 해야됨
예를 들어서 bubble sort -> mergesort 사용하면 다중코어에서 이득임 ㅇㅇ

코어가 늘어난다고해도 ideal하게 늘어나지 않는다.

전체 job의 시간을 보면 병렬처리가 가능한부분 sequential처리가 가능한 부분이 나뉜다.
아무리 코어 많이 달아서 병렬부분 시간 줄인다고해도 한계가 있다.

40%의 일을 2배로 올리면 총 1.25배 상승

한계가 있다
Granularity
Granularity = task의 size
task를 어떻게 core에 주냐에 따라서도 성능이 달라진다
coarse-grain : 크게
fine-grain : 작게
Frequent coordination가 over head를 만드는데 fine-grain이 더 손해다(계속해서 관리해줘야하니까)


왼쪽처럼 딱딱 쪼개서 되는경우는 잘없다. 오른쪽처럼 의존성이 발생해서 앞의 task가 끝나야지 실행되고 이런경우 많음
ex) merge전에 sort를 해야된다
완료시간의 최소는 가장 길게걸리는 path의 시간이 좌우한다.
Heterogeneity
분배한 task가 불균등할수도 있다.

요약 : 병렬화는 중요하지만 여러 문제가있다.

2번째 문제들

synchronization?

Consistency를 유지해야한다

일관성도 정도에 따라 나뉜다.
aws s3가 weak consistency고 고장났을때 보호를 위해 replica 3개 저장해논다.
여기서 생각해봐야할게 eventual로하면 replica가 즉시 업데이트 되지는 않는다. 그렇다고 strong으로 하면 너무 손해임
그래서 중간으로 합의한거임 ㅇㅇ
과제로 나온 article보면 알 수 있다.
다음으로 배울거

How can we achieve better consistency?
Key insight: Code has a critical section where accesses from other cores to the same resources will cause problems
그렇다면 Mutual exclusion 해준다.
Enforce restriction that only one core (or machine) can execute the critical section at any given time
critical section 에는 한개의 core만 접근하도록 제한

locking으로 Mutual exclusion 보존
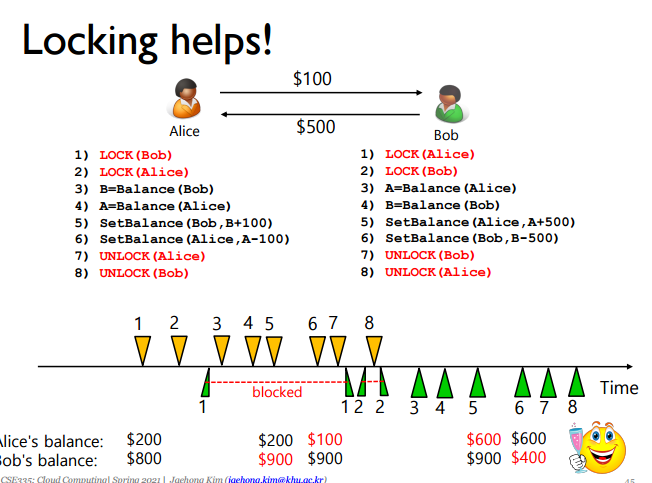
근데 locking만으로는 문제가 있는데 Deadlock이 발생할 수 있다.
다음할거

share하면 생각할게 많으니까 shared-nothing으로 생각해보자
구조들 보자


위에거가 점점 집적되면 core와 memory의 물리적 거리가 멀어진다. 이것도 영향있음 그래서 memory도 각각 가진다.
smp보다는 scalability는 좋아지는데 각자 메모리가지고있으니까 consistency같은거 고려해야됨

scalability 좋다. 몇개를 붙치든 상관없음
근데 이런것들을 처리할 framework가 필요함(hadoop spark 등등)
'학교공부 > 클라우드' 카테고리의 다른 글
| 7장(EBS) (0) | 2021.05.16 |
|---|---|
| 6장 (0) | 2021.05.12 |
| 클라우드 5장 (0) | 2021.04.10 |
| 클라우드 컴퓨팅 4장 (0) | 2021.04.01 |
| 클라우드 컴퓨팅 3/11 (0) | 2021.03.12 |



