관계대수 - SQL로 둘다 표현 할줄 알아야한다.
디비전자는 편의를 위해 만들어진거다. 필수 연사자로 디비전을 만들어보자 (여집합 사용, 시험문제)




인터페이스는 두개
대화식은 콘솔창 이용해서 사용
아래는 호스트 언어 + 내포된 SQL
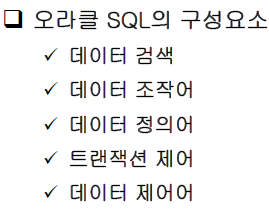
검색 & 조작

INSERT DELETE UPDATE 조작
SELECT 검색

데이터 정의어
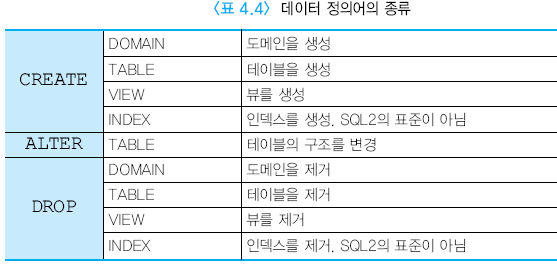
인스턴스가 아닌 스키마를 제거 변경 생성

AUTHORIZATION 소유자
RESTRICT 스키마안에 데이터 없을 때 삭제
CASCADE 걍 다 삭제

밑에 세줄은 무결성 제약조건 거는거??
찾아볼것

고정길이 -> 공간 낭비
가변길이 -> 비교할때 힘듬
그래서 보통 길이가 안변하고, 비교가 많은건 고정길이로 저장


제약조건
NOT NULL : null 허용 안함 default로는 허용함
UNIQUE : 중복 허용안함
default check primary key foreign key 등 등등

이런식으로 두개 사용해서 제약할 수도 있음.
삭제할때 네가지 모드

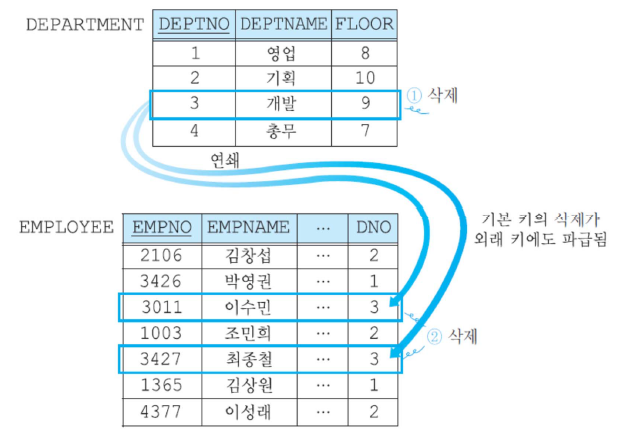


기본적인 SQL 질의

별칭 사용 가능

DISTINCT 사용하면 중복된 데이터 삭제됨, unique하게 만들어버림

특정 투플 검색 비교연산자 다양한거 사용가능

문자열 비교
문자열 비교할때만 LIKE 사용 %,- 사용

이% -> 이씨성
이- ->성이 이씨인 외자사람들
ex)
SELECT *
FROM EMPLOYEE AS E,
DEPARTMENT AS D
WHERE D.DNO = 2;
다수 검색 조건

요런건 잘못된거

위에거는 알맞는거임 ㅇㅇ

요런식으로도 가능
IN사용하면 연산자 쓸필요없이 편하게 사용가능

SELECT절에 산술 연산 가능
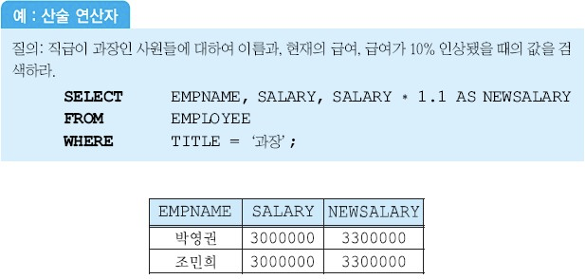
널값
널값을 포함한 다른 값과 널값을 연산하면 결과는 널값
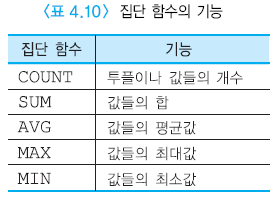
COUNT(*)를 제외한 집단 함수들은 널값을 무시함
// count는 튜플개수 세는건데 얘는 null포함해서 세준다
어떤 애트리뷰트에 들어 있는 값이 널인가 비교하기 위해서 DNO = NULL 처럼 나타내면 안됨
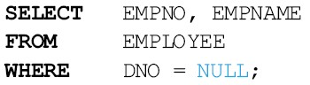
NULL > 300
NULL <> 300
이런거 그냥 다 결과는 NULL 따라서 위의 식을 아래와 같이 변경해 줘야한다.

반대는 IS NOT NULL
null하고 연산

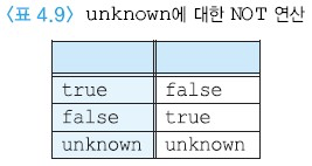
true = 1, false = 0, unknown = 0.5 C1 AND C2 = min(C1, C2)
C1 OR C2 = max(C1, C2)
NOT(C1) = 1 ‐ C1
산술 연산으로도 표현 가능
ex)
범위 비교할 때
SALARY BETWEEN 300 AND 400
1,3 아닌 부서
DNO NOT IN (1, 3)
SELECT 애트리뷰트 list => expression list
FROM
WHERE ....
expressioin : 단일 값을 나타내는 식
- 애트리뷰트 : DNO
- 산술식 : SALARY * 1.5
CASE 애트리뷰트 when 값1 THEN 값x
when 값2 THEN 값y
else 값z
end
만약
SELECT EMPNAME, SALARY
FROM EMPLOYEE,
에서 salary에 따라 다르게 출력하고 싶다면 어떻게 할까?
SELECT EMPNAME, case
when salary > 500 then '와우'
when salary < 100 then '에휴~'
else '오케이'
end
FROM EMPLOYEE
10/8

nullisfirst nullislast로 지정할수도있음





HAVING


ex) 만약 직급 순서대로 출력하고싶으면 어칼까?
SELECT *
FROM EMPLORYEES
ORDER BY TITLE;
하면 가나다순으로 오름차순되어버림
따라서
ORDER BY CASE TITLE WHEN '과장' THEN 1
WHEN '대리' THEN 2
else
end
이런식으로하면 됨
| A |
| 1 |
| 2 |
| 3 |
| null |
SUM(A)는 6
AVG(A)는 2
null값 무시
COUNT(A)는 3
COUNT(*) = 4 여기서만 특별하게 null포함


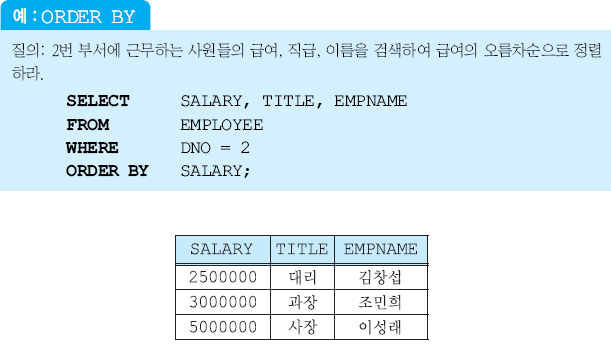
두개 이상의 릴레이션에서 검색




결과는 밑에 테이블에서 EMPNAME하고 DEPTNAME 프로젝션한거임
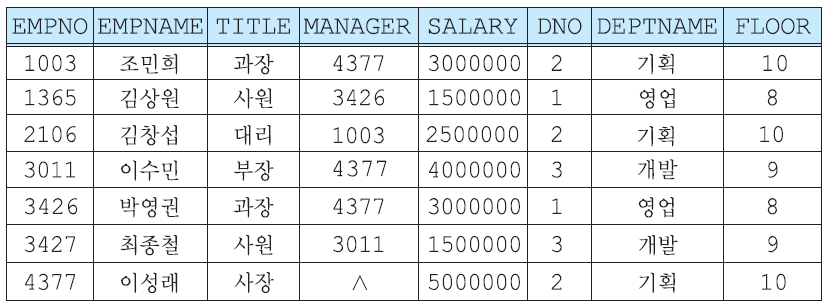
자체조인

과정

결과

select *
from A, B
where A.x = B.y
select *
from A INNER JOIN B ON A.x > b.y and A.xx = B.yy;
OUTER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN CROSS JOIN(카티션 곱)
UNION / UNION ALL # ALL하면 중복제거안함.
INTERSECT / INTERSECT ALL #ALL하면 중복허용 { A A B} {A A A B} 면 {A A B} (all)
별칭은 AS ""로 표현 별칭에 공백없으면 ""생략가능
DESCRIVE employees ( 테이블 구조 보임 live sql에서는 그냥 메뉴에 schema 검색)
릴레이션이나 스키마 애트리뷰트는 대소문자 구분 안함
인덱스란 key 값 pointer 쌍들의 집합. 튜플 식별자
Unnamed constraint 삭제할라면 어카지?
사용자를 위한 공간과 데이터베이스 자체를 위한 메타공간은 다르게 저장된다.
시스템 카탈로그나 data 딕셔너리에 직접 접근해서 삭제한다.
% 0개이상
- 하나
%영% 영들어간 모든이름
'학교공부 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 4 -5 (0) | 2020.10.21 |
|---|---|
| 실습 모음 (0) | 2020.10.21 |
| 데이터베이스 4장 관계대수 (1) | 2020.09.20 |
| 데이터 베이스 2장(관계 데이터 모델과 제약조건) (0) | 2020.09.20 |
| 데이터베이스 시스템 1장 (0) | 2020.09.03 |



