규제(regularization)
기계학습에서 가장 중요한건 일반화 학습이다.
일반화 성능을 높히는 거에 초점을 맞춰서 연구해왔다.
일반화 성능이란 테스트집합에서의 좋은 성능을 보이는것.
여기서 규제란 기계가 over-fitting 되지 않도록 적절한 가이드를 제공하는것.
데이터 확대
가장 강력한 규제 방법
모델 차수가 높더라고 데이터가 충분히 많으면 12차도 좋은 모델을 만들 수 있다.

샘플 개수가 많을 수록 overfiiting을 막고 일반화 성능을 높힐수있다.
근데 문제는
데이터 수집은 많은 비용이 듦
그라운드 트루스를 사람이 일일이 레이블링 해야한다.
레이블링이란 사람이 목표값을 메기는 행위.
이때 레이블한 결과값을 ground-truth라고 한다. 비슷한말로 참값 진리값
암튼 이게 많은 비용이 든다

그래서 옆에 그림처럼 인위적으로 데이터를 확대한다.
(돈아낌)
훈련집합에 있는 샘플을 변형한다. 약간 회전 또는 와핑(아래위로 옮기는 행위)
살짝살짝 바꿔서 데이터를 만든다
근데 적당히 바꿔야됨. 너무 바꾸면 아예 틀린 샘플이 생겨 성능이 하락할 수도 있다.
가중치 감쇠
데이터를 증가시키거 말고 좋은 방법이 있는데 모델링을 할때 매개변수의 모양을 조절해서 규제하는 방법.

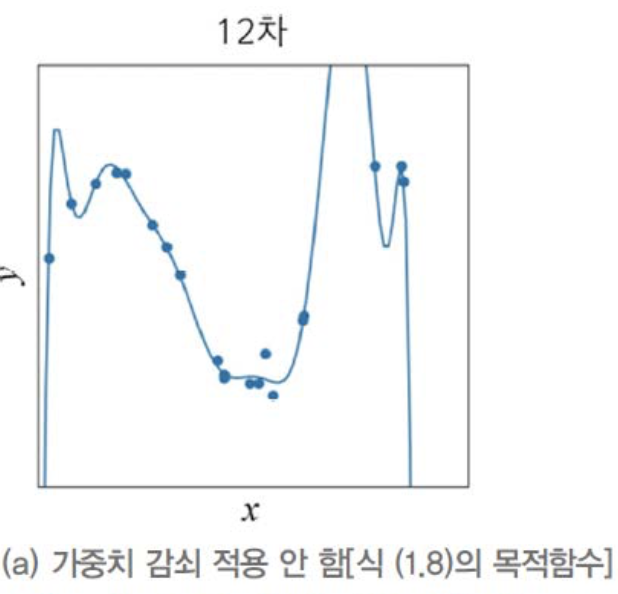
왼쪽처럼 선이 위아래로 들쭉날쭉 진동하는 것은 매개변수의 가중치가 매우 큰 것을 알아냄.
즉 노이즈까지 모두 학습한 모델은 가중치가 매우높다.
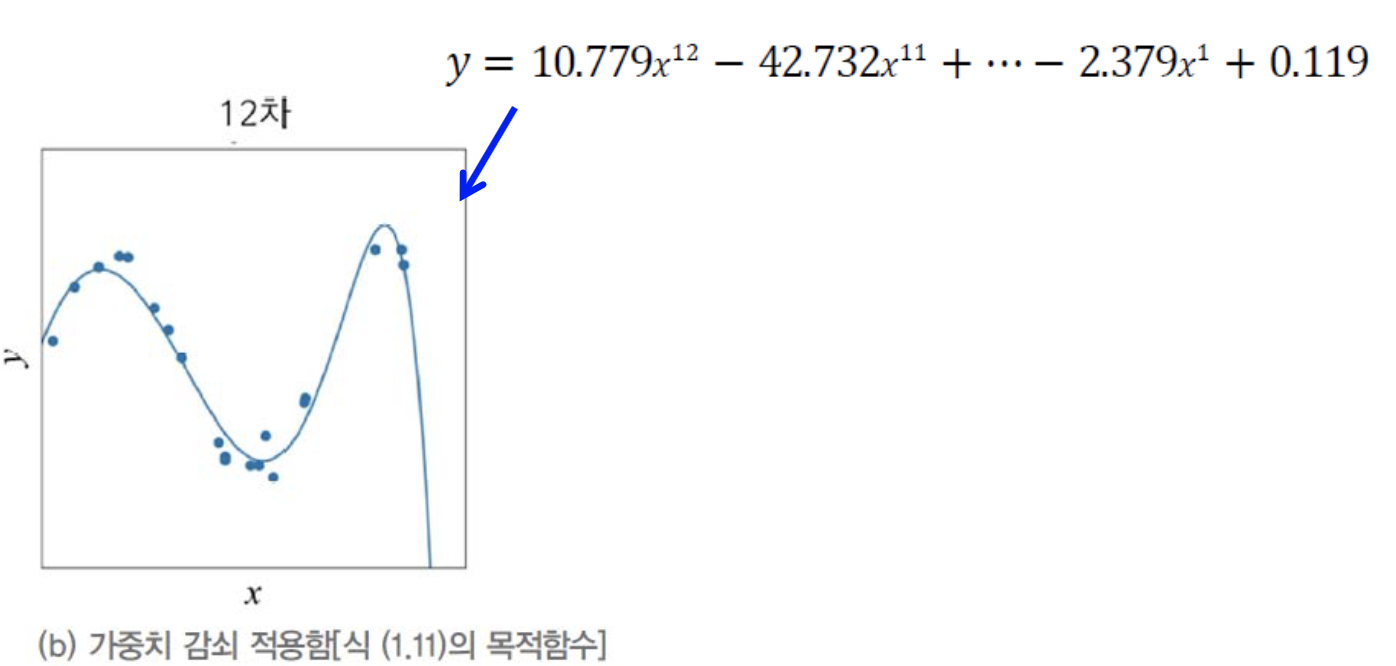
가중치를 적게 만들수록 부드럽게 만들어진다. 즉 over-fitting이 어느정도 해결되는 규제이다.
이처럼 가중치를 작게 만들어 선을 부드럽게 만드는 기법을 가중치 감쇠(weight decay)라고 한다.

여기서 저 ||θ||2는 가중치의 제곱을 의미한다.
따라서, 목적함수 = 오차를 줄이는 일 + 가중치를 줄이는 일
람다가 크면 클수록 오차를 줄이기보단 가중치를 줄이는데 집중할 것이다.
뒤에 식 의미
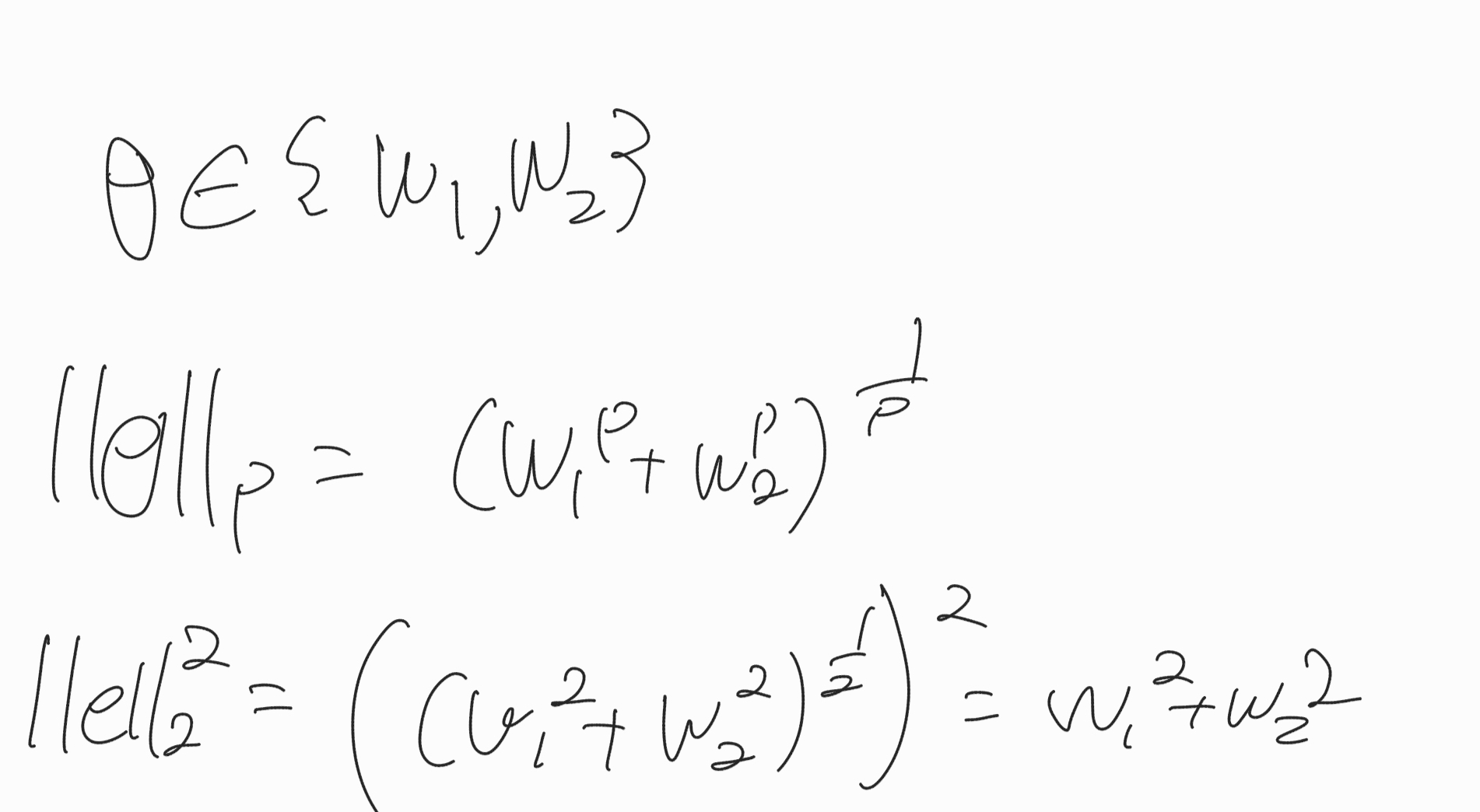
즉, 가중치 감소를 통해 규제를 해주면 (a) -> (b)처럼 일반화 성능이 좋아진다.
기계 학습 유형
지도 방식에 따른 유형

지도학습
특징 벡터 X와 목표값 Y가 모두 주어진 상황
회귀와 분류 문제로 구분
X -> [기계] -> Y
비지도학습
특징 벡터 X는 있는데 목표값 Y가 없는 상황
군집화 과업 (ex. 쇼핑몰 소비자 패턴 분석해서 맥주를 사는 사람은 오징어 땅콩도 산다. 군집화 가능)
밀도 추정, 특징 공간 변환 과업
6장의 주제
강화학습
목푯값이 주어지는데, 지도 학습과 다른 형태임. (강화학습에서 목푯값 = 보상)

ex) 쥐 미로에 넣어서 치즈(보상) 숨겨두면 쥐는 치즈를 점점 더 잘 찾을것이다.
바둑 테트리스 롤 등등 강화 학습 좋은 예
이기면 1, 패하면 -1하면 점점 더 이기는 방향으로 학습한다.
준지도 학습
일부의 데이터는 X와 Y 모두 가지지만 대부분 X만 존재.
{X, Y}, {X}
인터넷 덕분에 X의 수집은 쉽지만 Y는 수작업이 필요하여 최근 큰 중요성. 요즘 핫한거래
지도 학습(Supervised Learning)은 특징(features)이 이미 정해진 데이터를 사용하여 학습하는 방법입니다. 이 때 각 데이터에 정해진 특징은 레이블(label)이라고도 표현할 수 있으며, 레이블이 있는 데이터들의 집합은 트레이닝 세트(Training Set)이라고도 부릅니다.

일단 레이블이 있는 샘플들을 먼저 표시를 한다(a) 그다음 레이블이 없는 샘플들을 넣을때는 현재 있는 샘플에서 가까운 쪽에 복사해서 사용한다.(b)
오프라인 학습과 온라인 학습
온라인 학습 : 시간이 포함된 느낌??
오프라인 학습 : 그냥 데이터 뭉탕 학습 이 책은 오프라인 학습을 다룬다.
결정론적 학습과 스토캐스틱 학습
결정론적에서는 같은 데이터를 가지고 다시 학습하면 같은 예측기가 만들어짐
스토캐스틱 학습은 학습 과정에서 난수를 사용하므로 같은 데이터로 다시 학습하면 다른 예측기가 만들어짐. 보통 예측 과정도 난수 사용
분별(discriminative) 모델과 생성(generative) 모델
분별 모델은 부류 예측에만 관심. 즉 P(y|x)의 추정에 관심.
y1은 남자 y2는 여자라고 하자 만약 입력 영상 x가 들어왔을 때
p(y=y1|x) -> 60%
p(y=y2|x) -> 40%
남자일 확률이 60퍼이므로 남자로 예측한다
분별모델은 이처럼 입력 x가 들어왔을 때 남자냐 여자냐 예측해서 더 높은 값으로 추측하는것.
생성 모델은 P(x) 또는 P(x|y)를 추정한다
P(X)에 대한 추정이 무슨말일까 영상에 대한 추정을 생각할 수 있다.
쉽게 말하면 사람얼굴을 계속 넣어서 학습하면 고릴라 얼굴이나 낙서를 넣엇을 때 구분이 가능할 것이다.
그럼 이 P(x)를 통해 무엇을 할 수 있을까? 이걸로 새로운 샘플을 만들 수 있다.
겁나 많은 랜덤 영상을 P(x)를 통해 측정해서 높은 확률이 나오는 것을 샘플로 채택할 수 있다.
난이도 생성모델 >>>>>>>>> 분별모델
'학교공부 > 머신러닝' 카테고리의 다른 글
| pytorch lstm (0) | 2021.03.12 |
|---|---|
| 머신러닝 3 (수학) (0) | 2020.09.17 |
| 머신러닝 1장 (2) | 2020.09.11 |

