전에 배운 singlecycle에 pipeline을 더해서 성능을 획기적으로 상승시킴. 근데 이러면 여러문제가 발생한다.
pipeline hazard에는 크게 3가지가 있다.
- Structural hazard
: HW는 하나인데 같은 cycle에 두개의 명령어가 쓸라고함 - Data hazard
: 두개의 명령어가 같은 storage에 접근
: 명령어가 정순서로 뽑아질때 나옴 - Control hazard
: 한 명령어가 다음 명령어에 영향을 끼친다.
말로보는거보다 직접 봐보자
Structural Hazards

Structural Hazard는 ALU나 Memory에 자주 발생한다.
위의 그림처럼 동시에 접근하거나 아님 Floating 연산같이 ALU가 몇사이클 걸리는거는 pipeline이 늘어지면서 문제발생간단한 해결 방법은 Stall을 사용하는거다.

이렇게 bubble을 넣어서 한 클락 정지시키면 해결됨.

그래서 해결방법
1. 무식하게 Stall쓰기
2. hardware resource 사용 (multi-cycle resource를 사용하면 된다는데 어려워서 그냥 듣고넘김)
3. Harvard Architecture 같이 resource 복제한다. (data와 instruction 분리해서 받음// cost 늘긴해도 상황에 따라 좋은방법)
Data Hazards
data를 동시에 사용할 때 문제된다.
간단한 예를 들어보자

J 명령어가 실행될때 r1의 값이 아직 add가 완료된 상태가 아니라면 우리가 예상한 값이 아닌 엉뚱한 값으로 나올 수 있다. True dependence
그 외 경우


이럴때도 Data Hazards를 고민해야된다. 근데 우리가 배운 MIPS 5 stage pipeline에는 문제안되긴함.
Data Hazards의 해결방법
- stall 쓰기
: 간단하지만 성능 하락 - forward 방법 사용

자 문제상황을 보자 처음 add에서 WB으로 data가 적용되는 시점은 xor이 연산할 때이다. 따라서 xor 앞에 명령어는 다 data hazards 상태임.
여기서 forward 방식은 계산 끝난거를 바로바로 쏴주자는 거다.

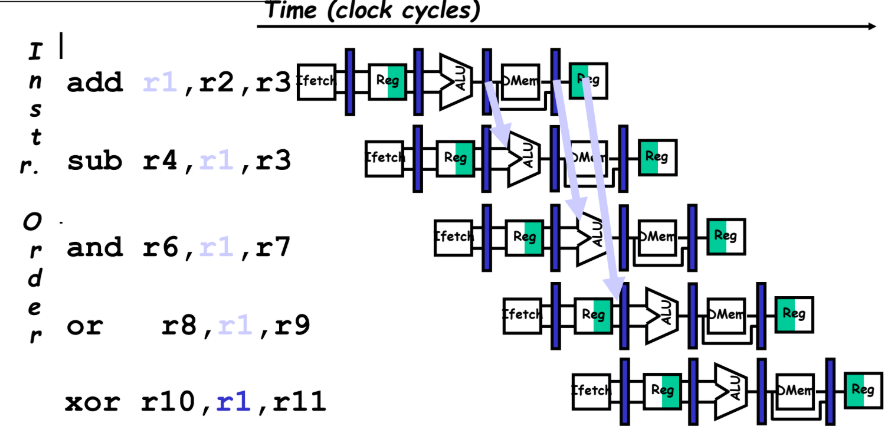
요렇게 ALU에서 연산 끝나고 바로바로 보내는 path 만들면 stall 줄이기 가능!
근데 다 쓸수 있는건 아니다. 만약 add가 아니라 lw 명령어라면 ALU가 아닌 Dmem에서 r1이 결정되서 어쩔수 없이 stall 써야함.

빨간색 부분은 해결못함. 그냥 stall 써야한다.

++ stall을 줄이는 방법 (compiler이용)

요런 경우 lw 다음에는 stall 발생한다고 했다.
근데 이걸 이렇게 바꾸면?

어차피 버리는 cycle에 프로그램에 영향없는 lw 가져와서 쓰면 개이득임. 똑똑한 컴파일러가 있으면 이렇게 stall을 줄일 수 있다.

Control Hazards
사실 앞에 두가지 문제보다 이게 큰 문제임 뒤에서 control hazard를 해결하는 여러 방법들을 배울거임.

beq 명령어 뒤에나오는 branch 계열 명령어는 ALU에서 계산을 해야지 jump 할지 말지 나온다.
만약 위에 명령어가 jump한다면 12,16라인은 버려야됨.

위에서 했던것처럼 간단히 연산결과 나올때까지 stall 쓰면 되지 않을까?
-> bracn가 한 프로그램의 30프로는 된다. 성능 개박살남
따라서
- 가냐 안가냐를 빠르게 알아야 되고
- branch 하는 address를 빠르게 얻어와야한다.
여러 방법들을 살펴보자
1. stall
간단하지만 성능 별로임
2. Predict Branch Not Taken
branch가 틀렸다고 가정, 가정 맞으면 좋고 아님말구
3. Predict Branch Taken
branch가 맞다고 가정, 보통 2번보다는 확률 높음
4. Execute Both Path
cpu 두개로 branch 만나면 두개다 쓰자는건데 무식하고 비싼 방법
5. Delayed Branch
이것도 위에거처럼 순서 바꾸는건데 Branch 연산하는동안 영향안받는 다른 명령어 가져와서 먼저 수행하게 하는거
6. Taken backwards Not taken Forwards
taken backward : for문이나 while문 같은건 Taken이라 가정
Not taken Forwards : if문 같은건 not Taken
보통 for문이나 while문이 반복할 확률이 높아서 성능 나쁘지 않음.
그외 pipeline을 힘들게 하는것들
MIPS에서는 다 한 사이클에 완료된다고 했지만 실제로 메모리같은거 접근하면 몇 cycle 더 걸리니까 bubble생김
ADdd Multi divide floating 연산은 각각 latency가 달라서 ALU가 연산하는 동안 그냥 기다려야됨
다음에는 branch predict를 배운다
'학교공부 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조 13 - Branch Prediction (0) | 2020.06.16 |
|---|---|
| 컴퓨터구조 12 - Branch Prediction (0) | 2020.06.15 |
| 컴퓨터구조 9 - Pipeline (0) | 2020.06.15 |
| 컴퓨터구조 SingleCycle (0) | 2020.06.15 |
| 컴퓨터구조 MIPS - 2 (0) | 2020.06.14 |



