
프로그램 내부에서 사용하는 주소 logical(virtual)
실제 메모리에 올라가는 주소 physical
밑에와 같은 프로그램을 실행시켜보면
#include <stdio.h>
int n = 0;
int main ()
{
printf (“&n = 0x%08x\n”, &n);
}
% ./a.out
&n = 0x08049508
% ./a.out
&n = 0x08049508n에 대하여 같은 주소가 나오는데 이는 실제로 같은 physical한 주소로 올라가는 것이 아니다. 프로그램 내부에서 사용되는 주소가 출력되므로 같은 값이 나오는 것이다.
MMU
이전 시간에 excution time에 memory를 binding할때 도와주는 hw인 mmu에 대해서 간략하게 배웠다.
이러한 mmu는 어떻게 설계 되어야할가?
첫번째로 할수 있는 생각은 단순히 ADD 기능만 가지는 것. 시작 주소 값을 더해서 변환한다.

만약 접근 불가능한 영역에 접근하려고하면 trap을 발생시켜 처리한다.
근데 이러한 풀이에는 조건이 필요한데 Contiguous Allocation 연속적으로 프로세스들이 할당되어있어야한다.
그래야지 시작주소만 알고 나머지를 구할수 있다.
Contiguous Allocation

요런 방식으로 연속적으로 할당한다. 이런 많은 프로그램을 할당하다보면 공간에 비는 곳이 생긴다.
이러한 곳을 Hole이라고 한다.
이러한 Hole 때문에 Fragmentation이 발생한다.


단편화에는 두가지 종류가 있는데
- 내부 단편화 : 페이징을 할 때 생길수 있는 현상. 필요한 메모리 양보다 더 큰 메모리가 할당되어서 낭비되는 상황.
- 외부 단편화 : 여유 공간이 여러 조각으로 퍼져있어서 연속적으로 할당하지 못해 못쓰는 상태.
그럼 이러한 holes들을 안생기게 할 수 없을까? compaction

- First-fit : 처음 생기는 hole에 그냥 넣는다
- Best-fit : process의 크기와 가장 비슷한 hole에 넣는다
- Worst-fit : 차이가 가장 큰 곳에 넣는다
근데 best나 worst는 모든 hole다 조사해야되서 overhead가 크다.
First, Best -fit 방법이 젤 성능상 낫다고한다. 근데 어차피 안쓰는 방식임
암튼 처음으로 돌아가서 연속적으로 배치하지 말아보자
Paging

physical memory는 fixed-sized block(frames) <-> logical memory frame과 같은 size의 block(pages)
같은 크기인 page로 process를 잘게 쪼개서 사용한다. 같은 크기니까 external Fragmentation 안생긴다. internal Fragmentation은 마지막 page에서 생길 수 있다. 현재도 쓰이는 방법
하지만 이러한 방법으로 전에는 address 변환 시 시작주소에서 편하게 더하기만 했던 방법을 손봐야한다.

모든 주소는 page number 과 page offset으로 나눠진다.

프로세스의 모든 pages를 기록해둔 page table을 만들어서 logical address를 쓸 때 page정보도 추가해준다.
p : page number
d : page offset
즉 page table을 통해 d번째 offset을 가르킬 수 있다.
Paging 예시

32bit 4GB memory 체계에서 page size가 4KB라면 offset은 4*1024 12bit를 할당해준다. 총 메모리가 2^32고 page size가 2^12 이므로 page number 개수 즉, table entires는 2^20이 된다.
Logical address가 00004/AFE라면 page table에서 page number에 맞는 실제 physical한 주소 가져와서 offset과 합쳐서 address 만들어낸다.

이렇게 page table을 활용해서 logical address를 physical address로 변환
변환 과정을 생각해보면 일단 각 process마다 page table이 존재하고 각가의 페이지가 있다. 따라서 process 1의 page 1234 process 2의 page 1234가 있을수 있다. 이것들의 실제 위치(frame number)를 찾아주는 방법이 page table인 것이다. 즉 page number + page table = frame nuber, frame number + offset = physical address 이다.(맞나?)
Frame Table
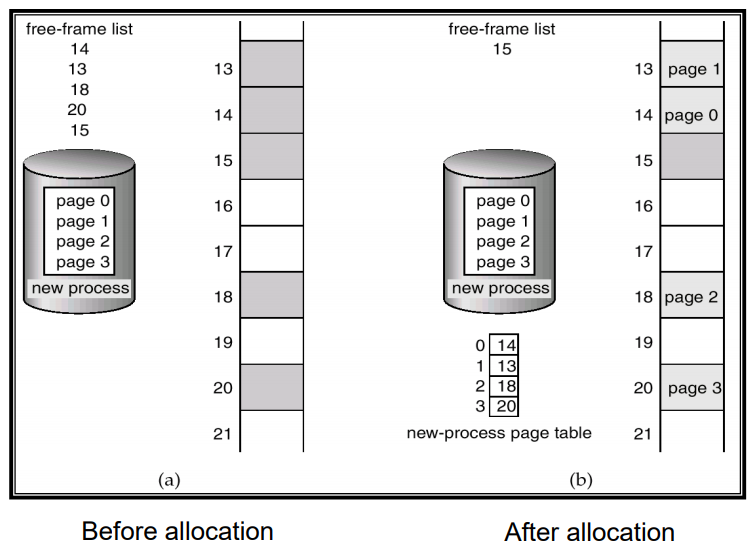
새로운 프로세스(페이지)가 할당 될려고 하면 빈프레임에 할당 되어야한다. 따라서 os가 free-frame list를 관리하면서 빈곳에 할당해줌.
paging의 HW구현
페이지 테이블은 프로세스마다 가지는 data이므로 process control block에 page table pointer을 저장한다.
첫번째 구현 :
- high-speed hardware registers로 구현하기, context swtich 마다 교환해줘야 해서 overhead가 늘긴하지만 빠르다.
- 문제점 page table이 커지면서 register로는 감당불가
두번째 구현 :
- page table을 main memory에 올리고 얘를 가르키는 page-table base register (PTBR)를 사용. context swtich 시에 이놈만 바꿔주면 되니까 시간 크게 단축시킴.
- 근데 메모리 접근할라고 page table접근하면 또 메모리 접근해서 접근시간 두배 됨 개손해
+ TLB (translation look-aside buffer)
이를 해결 하기위해 작고 빠른 hardware cache(TLB)를 사용한다. 성능저하되면 안되기때문에 보통 32개에서 1024개의 entry를 저장할수 있는 작은 hw.

CPU에 의해 logical adrress 생성되면 MMU는 먼저 TLB를 뒤진다. page 번호가 발견되면 즉시 frame number로 변경되며 이는 속도저하를 안시킴.
TLB miss 나면 page table가서 찾는다.
TLB 꽉 차면 LRU RR 등등 다양한 방법으로 replace 한다.
근데 만약 context swtich 시에는 TBL는 어떻게 될까?

ASID(address-space identifier)를 이용한다. 현재 실행중인 프로세스와 변환할려는 virtual address의 ASID가 다르다면 TLB miss를 낸다. ASID를 적용한 TLB는 여러 process의 page table을 가질 수 있다.
없으면 context swtich 시마다 flush해야됨
근데 ASID가 어떻게 적용되는지에 대한건 확실한 정보가없어서 모르겠다~
TLB 추가내용
- TBL miss handling은 intel cpu 기준 cpu에서 처리한다. os에서도 할 순 있는데 overhead 때문에 그런듯 자세히는 모르겠다~
- Locality 특성 때문에 TBL 적중률 꽤 높다
'학교공부 > 운영체제' 카테고리의 다른 글
| Virtual Memory Management (0) | 2020.05.29 |
|---|---|
| Memory Management Strategies - 3 (0) | 2020.05.25 |
| Memory Management Starategies (0) | 2020.05.20 |
| Deadlock (0) | 2020.05.15 |
| Synchronization (0) | 2020.05.09 |



